awk命令
简述
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
# 基本用法
awk '{print $1,$4}' testfile # 默认按空格或tab分割,输出文本1,4列
awk '{print $1 $4}' testfile # 区别是没有空格分开显示1,4列
awk '{printf "%-8s %-10s\n",$1,$4}' testfile # 格式化输出
awk参数
- -F fs or --field-separator fs:指定输入文件分隔符,fs是一个字符串或者是一个正则表达式,如-F:
- -v var=value or --asign var=value:赋值一个用户定义变量
- -f scripfile or --file scriptfile:从脚本文件中读取awk命令
-F:指定分隔符
awk –F: '{print $1,$7}' /etc/passwd # 指定:为分隔符,分割passwd
awk 'BEGIN{FS=":"} {print $1,$7}' /etc/passwd # 使用内建变量实现
awk –F '[:\/]' '{print $1,$7}' /etc/passwd # 使用:和/多个分隔符分割passwd文件
-v:设置变量
awk –va=1 '{print $1,$1+a}' log.txt # 字符串不会与数值相加,最后显示数值
awk –va=1 –vb=s '{print $1,$1+a,$1b}' log.txt # 设置多个变量
-f:指定awk脚本文件
# awk脚本格式:
BEGIN{
这里面放的是执行前的语句
}
{
这里面放的是处理每一行时要执行的语句
}
END {
这里面放的是处理完所有的行后要执行的语句
}
# 例子:
awk –f cal.awk score.txt # 通过awk脚本文件对成绩表进行格式化处理
awk脚本
awk工作原理
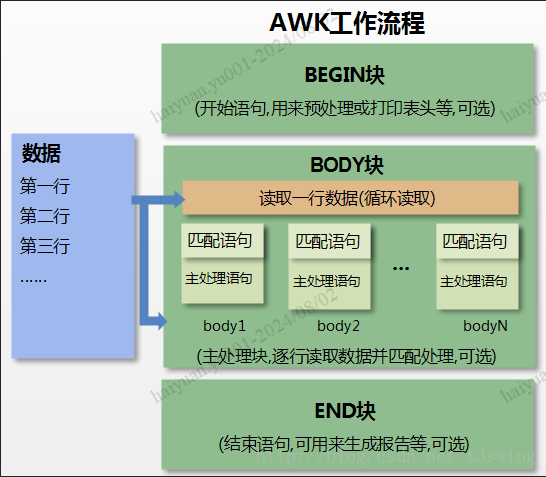
提示
- awk识别每行是通过\n换行符
- 按指定的分隔符划分域,$0 表示所有域(即一行内容),$1表示第一个域,$n表示第n个域
- awk一行行读取执行
awk脚本运算符
? : C条件表达式
|| : 逻辑或
&& : 逻辑与
! : 逻辑非
~ : 匹配正则表达式
!~ : 不匹配正则表达式
空格 : 连接
^,** : 求幂
$ : 字段引用
in : 数组成员
# 例子:
awk '$1>2 && $2=="test" {print $1,$2,$3}' testfile # 过滤第一列大于2并且第二列等于‘test’的行
awk内建变量
$n :当前记录的第n个字段,字段间由FS分隔
$0 :完整的输入记录
FS :输入字段分隔符(默认是任何空格)
OFS :输出字段分隔符(默认是空格)
RS :输入记录分隔符(默认一行是一条记录,所以默认记录分隔符是\n)
ORS :输出记录分隔符(默认是\n)
NR :已经读出的记录数,单个文件就是行号,从1开始
FNR :当前文件的记录数
NF :一条记录的字段数目
FILENAME :当前输入的文件名
ARGV :包含命令行参数的数组,ARGV[0]为awk,ARGV[1]为文件名
ARGC :命令行参数的数目,即ARGV的长度
ARGIND :当前正在处理的文件索引值,第一个文件是 1,第二个文件是 2,以此类推
ENVIRON :调用系统变量,如:ENVIRON[“PATH”]
IGNORECASE :如果为真IGNORECASE=1,则进行忽略大小写的匹配
# 例子:
awk –F: -f 1.awk testfile # 打印内置变量
awk正则字符串匹配
~ :表示模式开始
/…/ :匹配的模式
! :表示取反
# 例子:
awk '$1 !~ /Th/ {print $1,$4}' testfile
awk '!/re/' testfile # 省略~
awk编程
条件语句
# 格式一
if (…)
…
else
…
# 格式二
if (…)
…
else if (…)
…
else
…
循环语句
# for循环:
awk 'BEGIN { for (i = 1; i <= 5; ++i) print i }'
# while循环:
awk 'BEGIN {i=1;while(i<6){print i;++i}}'
# break跳出循环:
awk 'BEGIN {
sum = 0; for (i = 0; i < 20; ++i) {
sum += i; if (sum > 50) break; else print "Sum =", sum
}
}'
# continue结束当前循环:
awk 'BEGIN {for (i = 1; i < 20; ++i) {if (i % 2 == 0) print i ; else continue} }'
exit()
- exit()函数结束脚本程序的执行
- exit()函数默认参数为0
awk 'BEGIN {
sum = 0; for (i = 0; i < 20; ++i) {
sum += i; if (sum > 50) exit(10); else print "Sum =", sum
}
}'
数组
awk的数组底层数据结构是散列表,索引可以是数字或字符串
# 创建数组:
awk 'BEGIN {
sites["taobao"]="www.taobao.com";
sites["google"]="www.google.com";
print sites["taobao"] "\n" sites["google"]
}'
# 删除数组元素:
delete sites["google"]
# 模拟二为数组:
# awk本身不支持多维数组,但是可以通过一维数组模拟多维数组
awk 'BEGIN {
array["0,0"] = 100;
array["0,1"] = 200;
array["1,0"] = 400;
array["1,1"] = 500;
print "array[0,0] = " array["0,0"];
print "array[0,1] = " array["0,1"];
print "array[1,0] = " array["1,0"];
print "array[1,1] = " array["1,1"];
}'
函数
自定义函数
# 函数格式
function name(…)
{
…
}
# 例子:
awk –f functions.awk
内置函数
算术函数:
cos( x ):返回 x 的余弦;x 是弧度。
sin( x ):返回 x 的正弦;x 是弧度。
log( x ):返回 x 的自然对数。
rand( ):返回任意数字 n,其中 0<=n<1。
int( x ):返回 x 的截断至整数的值。
...
字符串函数:
gsub( Ere, Repl, [ In ] ):全局替换,将ere替换为repl。
sub(regex,sub,string):将第一次出现的子串 regex 替换为sub。
length [(String)]:返回字符串长度
index( String1, String2 ):在String1中查找string2,返回位置号,从1开始编号。如果 String2不在String1中出现,则返回 0。
match( String, Ere ):在 String中查找ere,ere可以是正则表达式,找到就返回位置,从 1 开始编号,否则返回 0。
substr( String, M, [ N ] ):在string从M开始截取长度为N的字符串
split( String, A, [Ere] ):将string以分隔符ere分隔,并将结果存入数组A
...
时间函数:
systime():得到时间戳,返回从1970年1月1日开始到当前时间(不计闰年)的整秒数
strftime([format [, timestamp]]):格式化时间输出,将时间戳转为时间字符串,如:8/7/2024 15:51:20
mktime( YYYY MM DD HH MM SS[ DST]):将字符串转为时间戳
位操作函数:
and(num1,num2):与
or(num1,num2):或
lshift(num,n):左移
rshift(num,n):右移
compl(num):按位求补
其他函数:
close(expr):关闭管道的文件
flush:刷新打开文件或管道的缓冲区
getline:读入下一行
next:停止处理当前记录,并且进入到下一条记录的处理过程。
nextfile:停止处理当前文件,从下一个文件第一个记录开始处理。
system(cmd):执行特定的命令然后返回其退出状态。返回值为 0 表示命令执行成功;非 0 表示命令执行失败。